Tonsser tech architecture
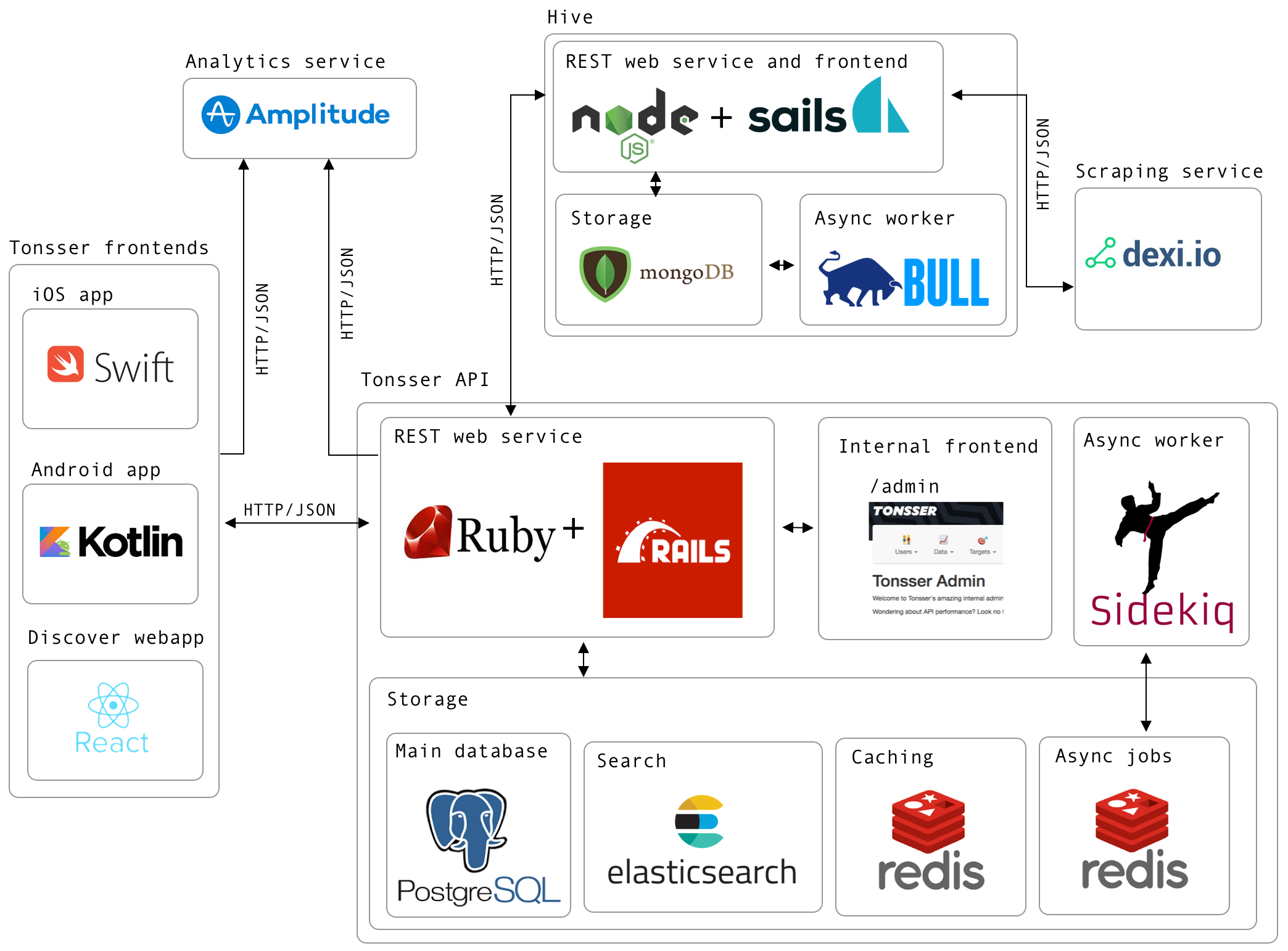
In this blog post I will go through the tech architecture in Tonsser and how the different parts integrates with each other. I will also dig more into the Tonsser API, which I’m responsible for. Lets start with going through each of the tech environments as shown in the image below.
Tonsser frontends
We have several frontends in Tonsser. Our iOS and Android mobile apps have been there for a long time, so they are heavy users of the Tonsser API. The communication between the clients and the API happens through HTTP, in this case using REST with JSON payloads. The iOS app is basically written 100% in Swift, whereas the Android team started transitioning the app from Java to Kotlin around a year ago. That codebase is currently 50% Kotlin and 50% Java.
Most of the traffic to the API happens through mobile apps as this is how our users log their football data. At the time of writing we have around 870K users registered in the database.
In 2018 we started to build a web app in React called Discover, which also integrates with the API in the same way as the mobile apps. Discover is a product that is focussed on the clubs and scouts, which means it has less users and thereby doesn’t generate the same amount of traffic to the API.
Tonsser API
The Tonsser API, which is what I’m mainly working on, is created in Ruby on Rails. Since the start, we have embraced TDD, which in retrospect was one of the best decision we have made in the backend team. Why that is, you can read more about here.
As already stated the Ruby on Rails app is mainly working as a REST API for all our Tonsser frontends, but it also integrates with our scraping system (called Hive), which I will discuss later in this post.
Besides the REST API for the frontends, we also have an internal admin web app in the API. This web app is used internally in the company for many different things.
Our primary datastore in the API is Postgres, as our data model is relational. However we also utilize the NoSQL like storage in Postgres, in this case raw JSON, for notifications and the feed.
Besides the Postgres database, we also use Redis for both caching and storing async jobs. For processing these jobs we use Sidekiq, as it utilizes threads, meaning we can run many jobs at the same time in the same process.
At last we use Elasticsearch for general search in the app. Primarily for user search and finding club/teams.
Since we are embracing TDD, we also like automation to achieve high productivity. Every time a commit is pushed to one of our git branches, the new code is automatically run through our CI pipeline on CircleCI. Deployments happen automatically if the tests are all green.
The app is hosted on Heroku, but we also use some AWS services, such as S3, SNS and ElasticTranscoder. For monitoring we use NewRelic and Librato.
Digging more into the Tonsser API
Here are some high level numbers to get an idea of the size and scale of Tonsser API today
- The API team is just me and David
- Over 4000 unit and integration tests
- Over 100k LoC, hence stuff inside of
/appof our Rails project. - PostgreSQL database
- 160GB of data
- 143 tables with around 342 million rows
- We currently use a Standard 5 database on Heroku
- At peak hours, we hit around 15K RPM, hence 250 req/s hitting the rails web service.
- To sustain this load, we use around 8 PL dynos
- We use Rails autoscale addon on Heroku to automatically scale dynos based on time in request queue, as our traffic fluctuates a lot.
- At peak hours our average response times is around 200ms and 95th percentile 500ms.
- To sustain this load, we use around 8 PL dynos
- At peak hours we can hit 10K RPM sidekiq jobs running.
- We have 3 different sidekiq processes running
- One for sending notifications
- One for nuking caches
- One for all other background jobs.
- We have 3 different sidekiq processes running
Analytics service
Tonsser is a very data-driven company, which means we track a lot of data on how our users are using our products. Especially on the mobile apps, as that is where the main interaction is.
We use a third party service called Amplitude, where we basically store all types of event data. Here we can easily build various dashboards and charts to understand how we can improve our product.
Dexi
The main foundation of Tonsser is scraping. We scrape all the relevant football federations sites in the countries we are in. This basically means, that when a user signups in our product, they can expect to find the team they are playing on in real life and all its related data, hence matches for the team, opponent teams etc.
We use a third party service called Dexi to handle all the scraping, hence running/building robots to scan and extract the necessary information from the football sites. Dexi integrates directly with Hive via webhooks.
Hive
Hive (Not Apache Hive), is the system that makes sure the Tonsser API is always in sync with what is present on the football sites. Meaning if something gets deleted, changed or created on any of the football sites, it is Hive’s job to forward this to the API.
Hive is currently built in NodeJS, uses MongoDB for storage due to the nature of scraped data.
Summing up
I could have gone in much more detail around the whole tech architecture and specifically stuff in the Tonsser API. However, if you want to know more about how we did certain stuff in the API, you are more than welcome to ask me, as it could be a good start for another blog post :)
